Employing a Multi-Scenario Framework for Continuous Learning and Comparative Analysis of Large Language Models in Sequence Task Prediction
Project Details
- Student(s): Maria Hanna and Abboud Hayek
- Advisor(s): Dr. Noel Maalouf
- Department: Mechatronics
- Academic Year(s): 2023-2024
Abstract
In the dynamic field of Natural Language Processing (NLP), technologies like voice assistants and advanced chatbots are increasingly important to our daily digital interactions, with auto-completion emerging as a crucial feature to enhance user experience and automate processes. This comprehensive research project delves into the performance of two prominent transformers, DistilBERT and RoBERTa, in auto-completion tasks, employing a variety of evaluation metrics such as accuracy, F1 score, and processing time to assess their effectiveness.
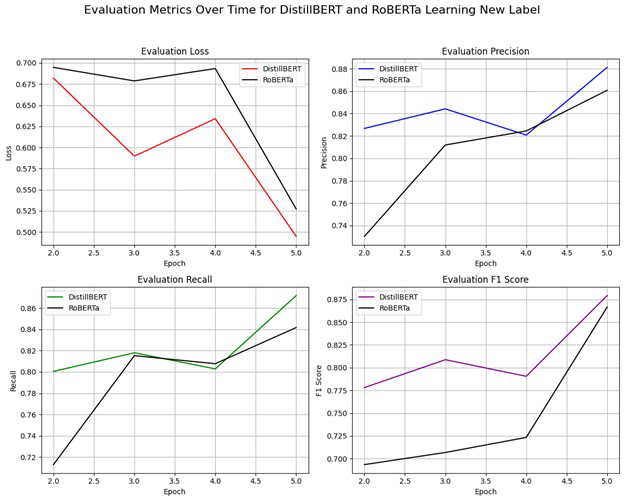
Initially, the study compares DistilBERT and RoBERTa using a tailored dataset with eight distinct labels, exploring their respective strengths in accuracy and processing speed. This investigation revealed that while RoBERTa exhibited superior accuracy, DistilBERT was more efficient in terms of speed. Building on these findings, our current research expands into the realm of incremental learning through user feedback. This approach is pivotal for adapting models to new information while addressing challenges like catastrophic forgetting, which was notably observed in RoBERTa when introduced to new data incrementally.
To enhance the adaptability and robustness of the models, an ensemble model is proposed combining the strengths of both DistilBERT and RoBERTa, aiming to offer a more balanced solution for NLP autocompletion tasks. This innovative strategy not only compares the static performance of the models but also evaluates their ability to evolve and refine outputs dynamically based on real-world user interactions.
The goal of enhancing human-robot interaction is central to this research. By improving the efficiency and adaptability of NLP systems in auto-completion tasks, we aim to facilitate smoother, more intuitive communication between humans and robotic systems, thus broadening the potential applications of the findings in this work.