Feature-Conditioned Symbolic Music Generation: Leveraging Latent Representations for Mood Expression
Project Details
- Student(s): Amir Amine
- Advisor(s): Dr. Joe Tekli | Co-Supervisor: Ralph Abboud, Ph.D.
- Department: Electrical & Computer
- Academic Year(s): 2024-2025
Abstract
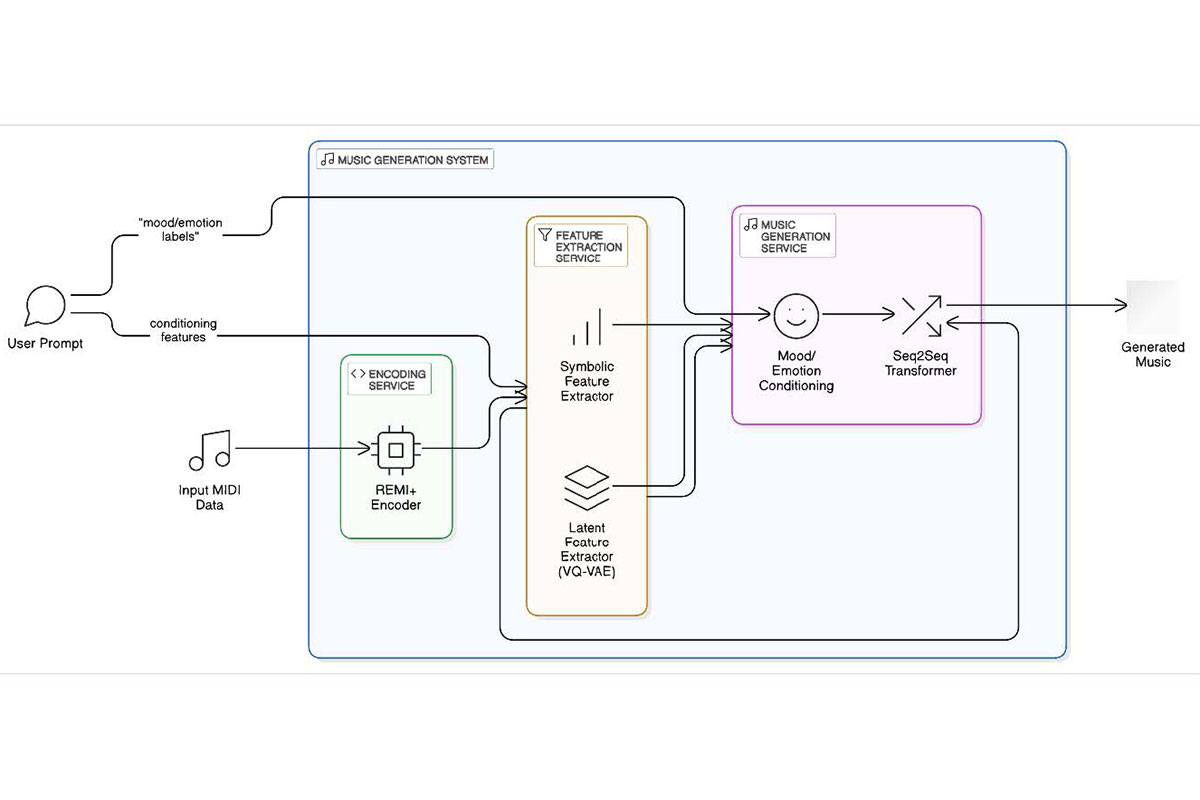
This paper presents a novel framework for conditional symbolic music generation that enables both learned and user-driven control through latent conditioning. Unlike previous approaches requiring explicit mood labels, the system harnesses inherent relationships between musical features and mood qualities by leveraging bar-level symbolic features and learned latent representations that statistically correlate with mood characteristics. The architecture employs a modular design with an Encoding Service that transforms MIDI into REMI+ representations, a Feature Extraction Service that creates symbolic and latent feature sequences, and a Music Generation Service built on a Seq2Seq Transformer architecture. Experiments demonstrate that generated music successfully preserves stylistic characteristics of reference pieces while maintaining musical coherence. Subjective evaluations reveal that synthetic compositions are often indistinguishable from human-created music, with participants rating AI-generated pieces slightly higher in expertise and originality than human compositions. The research also introduces a comprehensive taxonomy for evaluating symbolic music generation systems across five dimensions: Fluency, Fidelity, Diversity, Novelty, and Statistical Music Domain Metrics.