Performing Music Generation Using Stable Diffusion
Project Details
- Student(s): Ali Zayat
- Advisor(s): Dr. Joe Tekli | Co-Supervisor: Ralph Abboud, Ph.D.
- Department: Electrical & Computer
- Academic Year(s): 2024-2025
Abstract
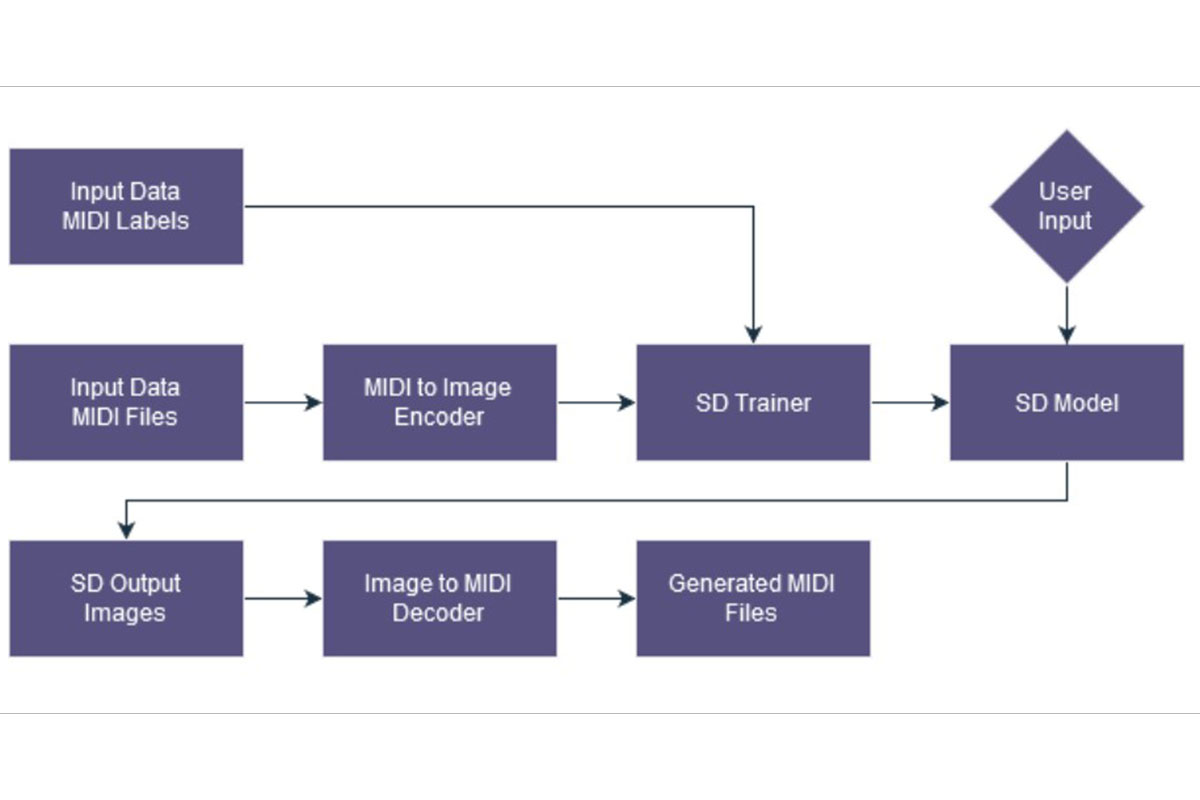
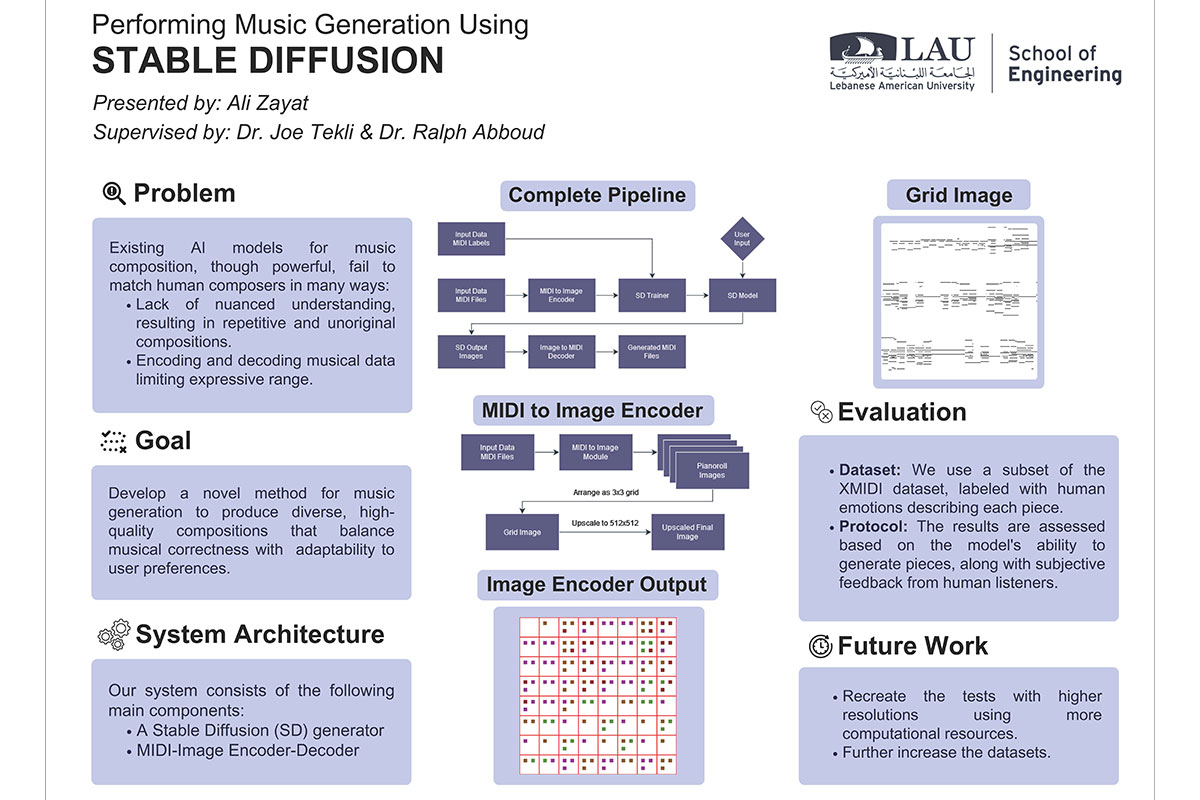
The rise of Artificial Intelligence (AI) and Deep Learning (DL) over the past few years has been unprecedented, with DL performing various complex tasks almost indistinguishably from humans, even in artistic domains. However, many notable frontiers remain such as the field of music generation, where widely known and utilized AI and DL models are still lacking. In this paper, we propose a novel method for generating music leveraging Stable Diffusion (SD) techniques. Our approach consists of a four stage pipeline: i) encoding input MIDI (computer music format) files as 2D images, ii) fine-tuning a SD model to process the encoded images, iii) using the SD model to generate new images based on the trained ones, and iv) decoding the generated images to produce new pieces of music. Our method’s results greatly depend on how the MIDI data is encoded and decoded, since it provides the main source of information for the SD model. The training images will be labelled using the artist’s name, emotions, and music genre representing the piece (e.g., Chopin, romantic, surprise, joy). This ensures that on the one hand, we have some control over the output, and on the other hand, that it is vague enough to allow new results to emerge. Through experimental validation, we plan to demonstrate the effectiveness of our method in generating high-quality musical compositions across various styles, emotions, and artistic expressions, paving the way for innovative applications in music production and composition assistance.